
There’s definitely a growing sense of urgency right now across the Salesforce ecosystem: “We need to get AI into our org.”
And with the release of Agentforce, that pressure has only been increasing. But here’s the uncomfortable truth most teams are overlooking: if your Salesforce data is already broken, Agentforce won’t solve it – rather, it will multiply it.
The Hidden Risk Behind AI in Salesforce
Most organizations have spent years investing in Salesforce automation. Flows. Validation rules. Approval processes. Reporting layers. On paper, everything looks sophisticated. But underneath? The data feeding those systems often tells a different story. Customer information still enters Salesforce through:
- Manual entry from PDFs or emails
- Phone-based intake
- Web forms without validation
- Disconnected systems and processes
And every one of those introduces inconsistency, duplication and gaps. As highlighted in a recent Salesforce Ben article, the issue isn’t what happens inside Salesforce – it’s what happens before the data ever gets there.
Why This Was “Manageable” Before
Historically, bad data was a nuisance, not a blocker.
- Sales reps caught obvious errors
- Ops teams cleaned things up downstream
- Reports were directionally “good enough”
It wasn’t perfect, but it worked. Until now.
Agentforce Changes the Equation
Agentforce doesn’t question your data. It doesn’t pause. It doesn’t validate context. It doesn’t “sense check” like a human would. It acts instantly and at scale – based on whatever is in your CRM.
That means:
- Duplicate records don’t just sit there → they trigger duplicate actions
- Missing fields don’t just get ignored → they break automations
- Inconsistent values don’t just confuse users → they misroute AI decisions
This is the core issue:
- AI doesn’t create bad outcomes – it amplifies existing ones.
- Or put more simply: flawed inputs = flawed outputs.
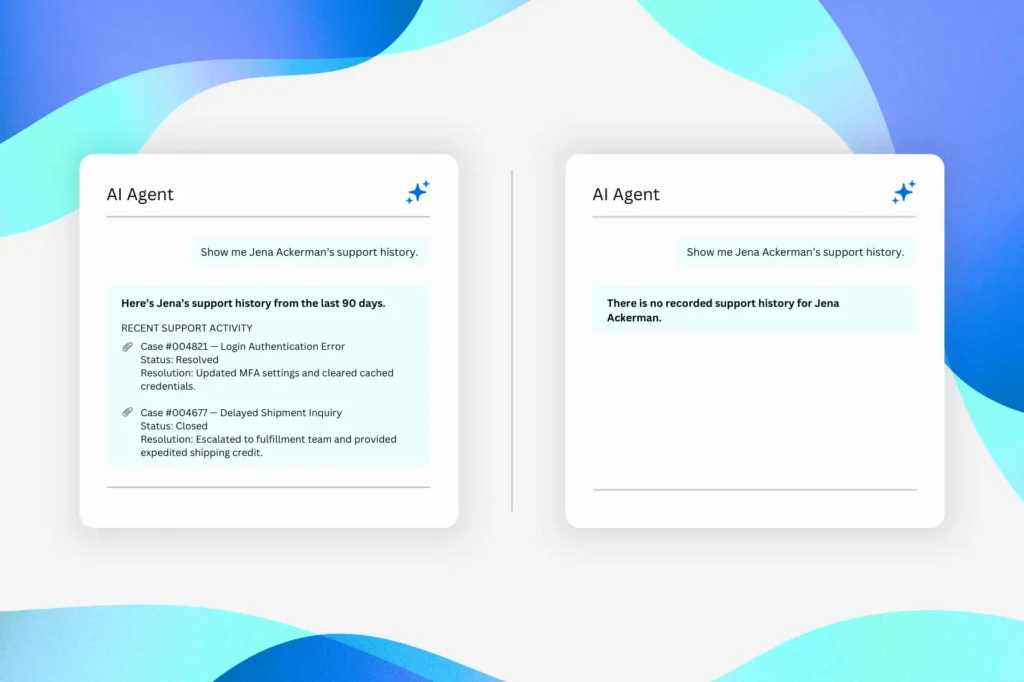
The Real Problem: Data Intake, Not Data Cleanup
When organizations recognize data issues, the instinct is to fix them inside Salesforce:
- Deduplication tools
- Validation rules
- Governance frameworks
All important – but all reactive. They address the symptom, not the source.
The reality is:
- You cannot clean your way out of bad data that was never captured correctly in the first place.
- Research shows poor data quality is one of the leading reasons AI initiatives fail to deliver value.
And in most cases, that poor data originates at the point of collection – not inside the platform.
What “AI-Ready” Data Actually Looks Like
For Agentforce (or any AI) to work effectively, your data needs to be:
- Complete – required fields consistently populated
- Consistent – standardized formats and values
- Accurate – reflects real-world truth
- Timely – updated in near real-time
Without these, even the most advanced AI layer becomes unreliable. And worse – it becomes confidently wrong.
The Shift: From Data Cleanup to Data Design
The organizations getting real value from AI aren’t just cleaning data. They’re redesigning how it’s created.
That means:
- Structuring intake at the source
- Enforcing validation before data hits Salesforce
- Eliminating manual re-keying wherever possible
- Creating guided, standardized user and customer inputs
In other words:
Stop fixing bad data after the fact. Instead, start preventing it from happening at all.
Where Trifecta Comes In
This is exactly where we’re seeing the biggest gap – and the biggest opportunity – with our clients today.
Teams are ready for Agentforce. But their data isn’t.
That’s why we’ve been helping organizations take a step back with a Salesforce Data Health Check, focused on:
- Data quality and completeness
- Duplication and fragmentation
- Intake and upstream processes
- AI readiness across core objects
Because before you scale AI, you need to trust what it’s acting on.
Final Thoughts
Agentforce is powerful. There’s no question. But it’s not a shortcut. It’s a multiplier.
So the real question isn’t: “Are we ready for AI?” It’s: “Is our data ready for AI to act on it?”




